Warum Edge Computing?
Nicht immer ist es von Vorteil, wenn IoT-Daten aus einem IoT-System zur Verarbeitung direkt in die Cloud transferiert werden. Mit Edge Computing geschieht eine erste Datenverarbeitung dezentral, «am Rand» des Netzwerks. bbv-Experte Michel Estermann erklärt die Vorteile dieser Technologie.

In herkömmlichen Cloud-Architekturen werden die gesammelten Daten aus einem IoT-System direkt in die Cloud transferiert, um sie dort zu verarbeiten. Grosse Datenmengen, etwa aus einem Sensoren-System oder von einem Industriestandort, werden über eine Internetverbindung an ein Rechenzentrum übermittelt. Dies bedingt eine hohe Bandbreite und eine hohe Verfügbarkeit. Je nach Bedarf müssen die im Rechenzentrum ausgewerteten Informationen direkt wieder verfügbar sein, etwa, um die Messwerte eines IoT-Systems in Echtzeit zur Verfügung zu stellen oder Informationen in einer Augmented-Reality-Umgebung darstellen zu können.

Die lange Reise von der Schweiz nach China

Wie China seine Daten schützt

Coffee-as-a-Service: Kundenerlebnis neu definiert

Wachstumschancen nutzen mit der Cloud
Trotz leistungsfähiger Infrastruktur können zu lange Reaktionszeiten entstehen. «Wenn ein unmittelbares Feedback erwartet wird und die Latenz möglichst kurz sein soll, dauert die Übermittlung zur Cloud und wieder zurück oft zu lange», sagt Michel Estermann, Senior Software-Ingenieur bei bbv. Gerade, wenn die räumliche Distanz etwa zwischen einem IoT-System und dem Rechenzentrum gross ist, entstehen unerwünschte Latenzzeiten. Auch wenn von einem Aussenstandort oder von einer Industrieumgebung sehr grosse Datenmengen via Cloud zentral verarbeitet werden, dauern Übermittlung, Verarbeitung und Rückmeldung oft zu lang. Solche Latenzzeiten müssen vermieden werden.
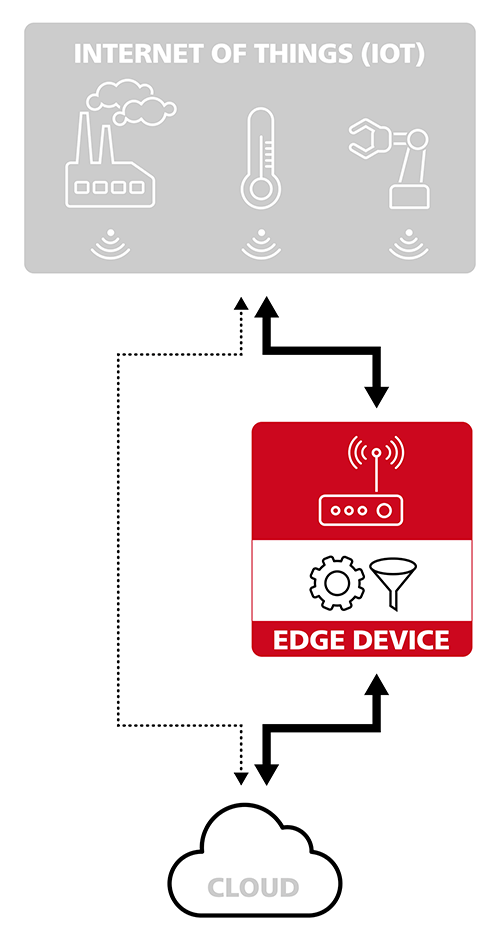
Datenverarbeitung «am Rande des Netzwerks»
Edge Computing macht die Verarbeitung und Übermittlung von Daten effizienter. Die Idee bei Edge Computing liegt darin, die Daten am Ort der Entstehung – also am Rand («Edge») des Netzwerks – zu filtern oder zu bearbeiten. So müssen beispielsweise nicht alle Daten an ein Rechenzentrum transferiert werden, sondern können von einem Edge-System gefiltert und/oder gebündelt werden. Werden nur die hochverfügbaren Daten an Ort und Stelle durch intelligente Devices verarbeitet, können jene Dienste, die auch längere Latenzzeiten erlauben, weiterhin in der Cloud verarbeitet werden. In diesem Fall werden die relevanten Daten herausgefiltert, sodass viel weniger Daten gesendet werden müssen. Irrelevante Daten bleiben zurück.
«Um Rückmeldungen noch unmittelbarer zu machen, können Daten vom Edge Device direkt vor Ort bearbeitet werden», erklärt Estermann. Eine weitere Strategie, um die Latenz zu minimieren sei es, im Edge Device mehrere Nachrichten zu einer einzigen zu bündeln, um so die zu übermittelnde Datenmenge zu minimieren. Durch die Vor-Ort-Bearbeitung und die Beschleunigung der Datenübermittlung können intelligente Anwendungen in IoT-Umgebungen praktisch in Echtzeit reagieren, was ein entscheidender Vorteil sein kann.
Sicherheit physisch und virtuell
Wenn mit Edge Computing sensible Daten vor Ort verarbeitet werden und nicht in die Public Cloud gelangen, entfällt das Sicherheitsrisiko bei der Datenübermittlung. «Doch muss man je nach Standort des Edge Devices bedenken, dass diese Knotenpunkte, welche die gesammelten IoT-Daten verarbeiten oder filtern, attraktive Ziele von Hackern sein können», sagt Michel Estermann. Deshalb müssen diese Edge Devices besonders geschützt werden. «Vor allem dann, wenn die Devices nicht innerhalb eines Industriestandorts installiert sind, sondern an einem Aussenstandort, wo die Geräte auch physisch vor Zugriffen und Manipulation geschützt werden müssen.»
Edge-Services der Cloud-Anbieter
Edge Computing ist eine noch junge Technologie. Während bisher der Aufwand für den Aufbau des Systems bzw. die Programmierung der Module relativ gross war, bieten mittlerweile Cloud-Dienstleister wie Microsoft oder Amazon komplette Edge-Services an – zum Beispiel Microsoft Azure IoT Edge oder AWS IoT Greengrass von Amazon. Anhand der Microsoft-Lösung erläutert Michel Estermann die Arbeitsweise eines solchen Services: «Azure IoT Edge arbeitet mit mehreren Edge-Modulen, die in einem Docker-Container vor Ort die Daten verarbeiten. Der sogenannte Edge Agent startet und orchestriert die Edge-Module. Edge-Module können miteinander verbunden werden und so eine Nachrichten-Pipeline bilden, welche die Daten verarbeitet oder filtert, bevor sie an den IoT-Hub in der Cloud gesendet werden.» Für die Kommunikation mit dem IoT-Hub ist der Edge-Hub zuständig. Er leitet ebenfalls die Authentifizierung von angeschlossenen IoT-Geräten ans Rechenzentrum weiter und speichert sie, um eine schnelle Authentifizierung bei späteren Verbindungen zu ermöglichen.
Gemäss Estermann ist der Einstieg in Edge dank der vorgefertigten Services einfacher. «Unternehmen, die ein IoT-System nutzen, müssen damit ihre Edge-Umgebung und die Anbindung in die Cloud nicht selbst aufbauen.» Weiter sei eine Offline-Unterstützung eingebaut. «Bei einer Störung der Verbindung zur Cloud sorgt diese dafür, dass die Daten im Edge Device für eine gewisse Zeit zwischengespeichert werden. Sobald die Verbindung wieder steht, werden sie an den IoT-Hub in der Cloud gesendet,» so Estermann. Werden die Daten komplett vor Ort verarbeitet, sorgt Edge Computing dafür, dass die Datenverarbeitung des IoT-Systems zumindest kurzfristig komplett unabhängig sowohl von Netzwerk- und Internetgeschwindigkeit als auch von einem Data-Warehouse geschieht.
Doch die Services haben je nach bereits vorhandener Infrastruktur durchaus ihre Tücken. Weil eine gewisse Abhängigkeit von Docker besteht, sei Azure IoT Edge vielleicht nicht die passende Lösung. «Die Hardware muss denn auch ausreichende Kapazitäten für das System bieten. Wird beispielsweise ein Raspberry Pi als Edge Device eingesetzt, können neben dem Edge Agent und dem Edge Hub nur noch zwei weitere Module für eigene Anwendungen eingesetzt werden.»
Günstig und schnell
Insgesamt erachtet Estermann Edge Computing – und insbesondere die Azure-Lösung, mit der er sich am besten auskennt – als eine vielversprechende Technologie. Dadurch, dass weniger Daten in die Cloud gesendet werden müssen, entstehen tiefere Netzwerkkosten als bei herkömmlichen Methoden, bei der die kompletten Datenströme in der Cloud verarbeitet werden. Gerade bei einer niedrigen Bandbreite sorgt die Filterung der Daten dafür, dass die Übermittlung schneller und ressourcenschonender ist. Zudem können Übertragungsverzögerungen und Ausfälle eingeschränkt werden.
Neben einer Reduktion der Bandbreite, geringerer Latenzzeit und einer Offline-Fähigkeit, können also auch Kosten und Cloud-Kapazitäten eingespart werden. Für Michel Estermann kann Edge Computing je nach Anwendungszweck und Voraussetzungen eines IoT-Systems die ideale Lösung sein. «Für viele Anwendungen ist das traditionelle Modell zu teuer und zu langsam. Es braucht deshalb dezentrale Lösungen, um die Anforderungen moderner IoT-Anwendungen erfüllen zu können.»

Der Experte
Michel Estermann
Michel Estermann ist Senior Software Engineer bei bbv. Er ist überzeugt, dass ein gemeinsames Verständnis der Vision, Ziele und Anforderungen essentiell für das Gelingen eines Projektes ist – ganz nach dem «Manifest für Agile Softwareentwicklung». Als Entwickler möchte er auch seinen Beitrag dazu leisten.
